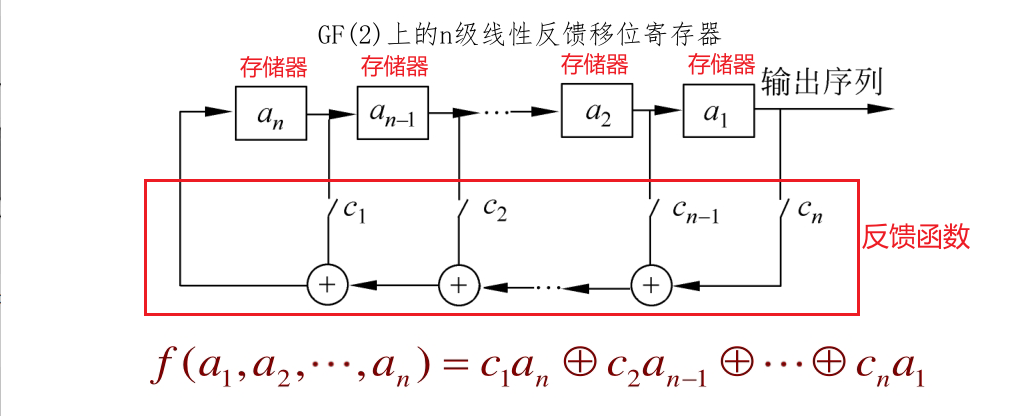
i := 0 j := 0 while GeneratingOutput: i := (i + 1) mod 256 //a j := (j + S[i]) mod 256 //b swap values of S[i] and S[j] //c k := inputByte ^ S[(S[i] + S[j]) % 256] output K endwhile
defcal_LCG_m(seq): t = [] for i inrange(1, len(seq)): t.append(seq[i] - seq[i-1])
T = [] for i inrange(1, len(t) - 1): T.append(t[i+1] * t[i-1] - t[i] ** 2)
m = [] for i inrange(len(T)-1): mm = GCD(T[i], T[i+1]) if isPrime(mm): m.append(int(mm)) else: for i inrange(1,100): if isPrime(mm // i): mm = mm // i m.append(int(mm)) break return m
defcal_LCG_a_b(seq, m): t = [] for i inrange(1, len(seq)): t.append(seq[i] - seq[i-1]) a = inverse(t[0], m) * t[1] % m b = (seq[1] - a * seq[0]) % m return (a, b)
#脚本1 import Crypto.Util.strxor as xo import libnum, codecs, numpy as np
defisChr(x): iford('a') <= x and x <= ord('z'): returnTrue iford('A') <= x and x <= ord('Z'): returnTrue returnFalse
definfer(index, pos): if msg[index, pos] != 0: return msg[index, pos] = ord(' ') for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
defknow(index, pos, ch): msg[index, pos] = ord(ch) for x inrange(len(c)): if x != index: msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
dat = []
defgetSpace(): for index, x inenumerate(c): res = [xo.strxor(x, y) for y in c if x!=y] f = lambda pos: len(list(filter(isChr, [s[pos] for s in res]))) cnt = [f(pos) for pos inrange(len(x))] for pos inrange(len(x)): dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x inopen('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1] for w, index, pos in dat: infer(index, pos)
know(10, 21, 'y') know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
key = xo.strxor(c[0], ''.join([chr(c) for c in msg[0]]).encode()) print(key)
#脚本2 #!/usr/bin/python ## OTP - Recovering the private key from a set of messages that were encrypted w/ the same private key (Many time pad attack) - crypto100-many_time_secret @ alexctf 2017 # Original code by jwomers: https://github.com/Jwomers/many-time-pad-attack/blob/master/attack.py)
import string import collections import sets, sys
# 11 unknown ciphertexts (in hex format), all encrpyted with the same key c1='daaa4b4e8c996dc786889cd63bc4df4d1e7dc6f3f0b7a0b61ad48811f6f7c9bfabd7083c53ba54' c2='c5a342468c8c7a88999a9dd623c0cc4b0f7c829acaf8f3ac13c78300b3b1c7a3ef8e193840bb' c3='dda342458c897a8285df879e3285ce511e7c8d9afff9b7ff15de8a16b394c7bdab920e7946a05e9941d8308e' c4='d9b05b4cd5ce7c8f938bd39e24d0df191d7694dfeaf8bfbb56e28900e1b8dff1bb985c2d5aa154' c5='d9aa4b00c88b7fc79d99d38223c08d54146b88d3f0f0f38c03df8d52f0bfc1bda3d7133712a55e9948c32c8a' c6='c4b60e46c9827cc79e9698936bd1c55c5b6e87c8f0febdb856fe8052e4bfc9a5efbe5c3f57ad4b9944de34' c7='d9aa5700da817f94d29e81936bc4c1555b7b94d5f5f2bdff37df8252ffbecfb9bbd7152a12bc4fc00ad7229090' c8='c4e24645cd9c28939a86d3982ac8c819086989d1fbf9f39e18d5c601fbb6dab4ef9e12795bbc549959d9229090' c9='d9aa4b598c80698a97df879e2ec08d5b1e7f89c8fbb7beba56f0c619fdb2c4bdef8313795fa149dc0ad4228f' c10='cce25d48d98a6c8280df909926c0de19143983c8befab6ff21d99f52e4b2daa5ef83143647e854d60ad5269c87' c11='d9aa4b598c85668885df9d993f85e419107783cdbee3bbba1391b11afcf7c3bfaa805c2d5aad42995ede2cdd82977244' ciphers = [c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, c11] # The target ciphertext we want to crack
# XORs two string defstrxor(a, b): # xor two strings (trims the longer input) return"".join([chr(ord(x) ^ ord(y)) for (x, y) inzip(a, b)])
# To store the final key final_key = [None]*150 # To store the positions we know are broken known_key_positions = set()
# For each ciphertext for current_index, ciphertext inenumerate(ciphers): counter = collections.Counter() # for each other ciphertext for index, ciphertext2 inenumerate(ciphers): if current_index != index: # don't xor a ciphertext with itself for indexOfChar, char inenumerate(strxor(ciphertext.decode('hex'), ciphertext2.decode('hex'))): # Xor the two ciphertexts # If a character in the xored result is a alphanumeric character, it means there was probably a space character in one of the plaintexts (we don't know which one) if char in string.printable and char.isalpha(): counter[indexOfChar] += 1# Increment the counter at this index knownSpaceIndexes = []
# Loop through all positions where a space character was possible in the current_index cipher for ind, val in counter.items(): # If a space was found at least 7 times at this index out of the 9 possible XORS, then the space character was likely from the current_index cipher! if val >= 7: knownSpaceIndexes.append(ind) #print knownSpaceIndexes # Shows all the positions where we now know the key!
# Now Xor the current_index with spaces, and at the knownSpaceIndexes positions we get the key back! xor_with_spaces = strxor(ciphertext.decode('hex'),' '*150) for index in knownSpaceIndexes: # Store the key's value at the correct position final_key[index] = xor_with_spaces[index].encode('hex') # Record that we known the key at this position known_key_positions.add(index)
# Construct a hex key from the currently known key, adding in '00' hex chars where we do not know (to make a complete hex string) final_key_hex = ''.join([val if val isnotNoneelse'00'for val in final_key]) # Xor the currently known key with the target cipher output = strxor(target_cipher.decode('hex'),final_key_hex.decode('hex'))
print"Fix this sentence:" print''.join([char if index in known_key_positions else'*'for index, char inenumerate(output)])+"\n"
# WAIT.. MANUAL STEP HERE # This output are printing a * if that character is not known yet # fix the missing characters like this: "Let*M**k*ow if *o{*a" = "cure, Let Me know if you a" # if is too hard, change the target_cipher to another one and try again # and we have our key to fix the entire text!
#sys.exit(0) #comment and continue if u got a good key
print'------end------' for i in ciphers: target_fix(i)
whileTrue: pts = [xor(key, c) for c in ct] for i, pt inenumerate(pts): print(i, pt) idx = int(input("Enter index: ")) if idx == -1: break c = input("Enter next char: ")[0] key += bytes([ord(c) ^ ct[idx][len(key)]]) print("Current key:", key.hex()) print([xor(key, c) for c in ct])
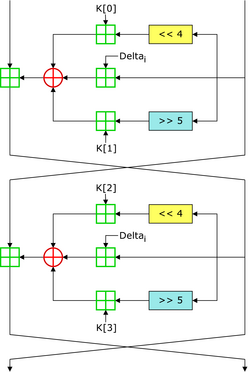
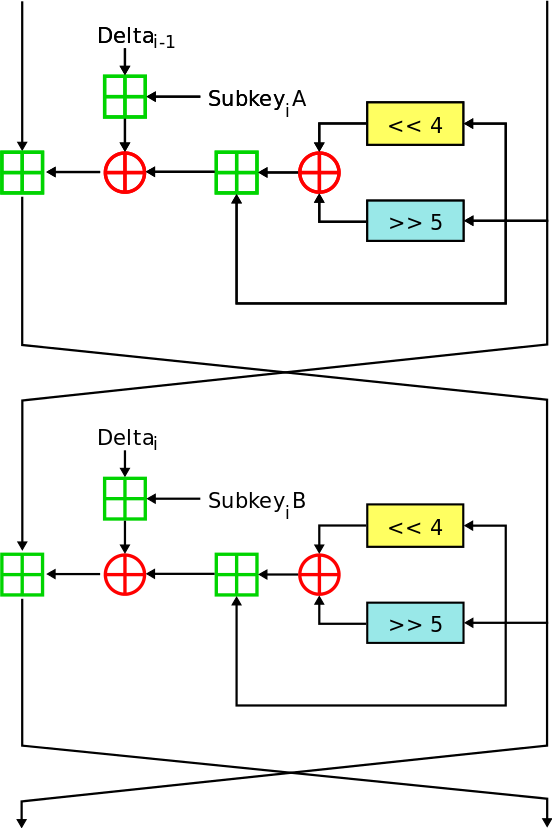
TEA / XTEA / XXTEA
TEA
微型加密算法(Tiny Encryption Algorithm,TEA)是一种易于描述和执行的块密码,通常只需要很少的代码就可实现。TEA 操作处理在两个 32 位无符号整型上(可能源于一个 64 位数据),并且使用一个 128 位的密钥。设计者是 Roger Needham 和 David Wheeler。
encrypted = [] for i inrange(len(plain)//2): now = encrypt(plain[2*i:2*(i+1)], key) encrypted += now
decrypted = [] final = b'' for i inrange(len(encrypted)//2): now = decrypt(encrypted[2*i:2*(i+1)], key) decrypted += now final += long_to_bytes(now[0])[::-1] + long_to_bytes(now[1])[::-1]
encrypted = [] for i inrange(len(plain)//2): now = encrypt(plain[2*i:2*(i+1)], key) encrypted += now
decrypted = [] final = b'' for i inrange(len(encrypted)//2): now = decrypt(encrypted[2*i:2*(i+1)], key) decrypted += now final += long_to_bytes(now[0])[::-1] + long_to_bytes(now[1])[::-1]
defenc_long(n): '''Encodes arbitrarily large number n to a sequence of bytes. Big endian byte order is used.''' s = "" while n > 0: s = chr(n & 0xFF) + s n >>= 8 return s
defreset(self, iv = None): '''Reset the cipher and optionally set a new IV (int64 / string).''' self.c = self.start_c[:] self.x = self.start_x[:] self.b = self.start_b self._buf = 0 self._buf_bytes = 0 if iv != None: self.set_iv(iv)
defset_iv(self, iv): '''Set a new IV (64 bit integer / bytestring).'''
ifisinstance(iv, str): i = 0 for c in iv: i = (i << 8) | ord(c) iv = i
defkeystream(self, n): '''Generate a keystream of n bytes''' res = "" b = self._buf j = self._buf_bytes next = self.__next__ derive = self.derive for i inrange(n): ifnot j: j = 16 next() b = derive() res += chr(b & 0xFF) j -= 1 b >>= 1
self._buf = b self._buf_bytes = j return res
defencrypt(self, data): '''Encrypt/Decrypt data of arbitrary length.''' res = "" b = self._buf j = self._buf_bytes next = self.__next__ derive = self.derive
for c in data: ifnot j: # empty buffer => fetch next 128 bits j = 16 next() b = derive() res += chr(ord(c) ^ (b & 0xFF)) j -= 1 b >>= 1 self._buf = b self._buf_bytes = j return res
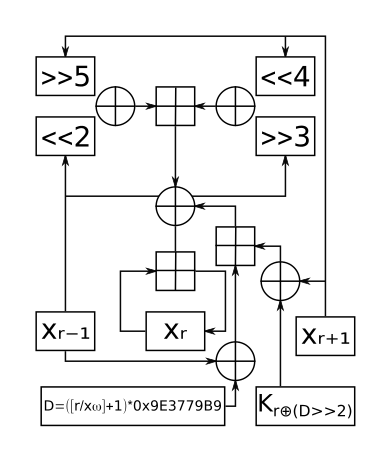
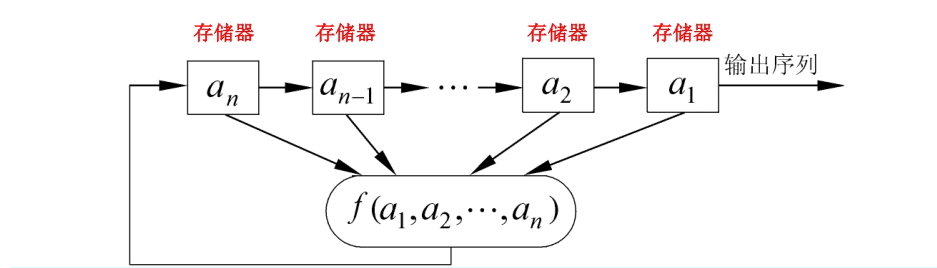
Xorshift 随机数生成器是 George Marsaglia 发明的一类伪随机数生成器。它们通过和自己逻辑移位后的数进行异或操作来生成序列中的下一个数。这在现代计算机体系结构非常快。它们是线性反馈移位寄存器的一个子类,其简单的实现使它们速度更快且使用更少的空间。然而,必须仔细选择合适参数以达到长周期。
问题:在循环移位异或加密中,我们已知变换后的密文 y ,以及多个偏移的密钥 ks ,要求出原文 x。
# 脚本1 # right shift inverse definverse_right(res, shift, bits=32): tmp = res for i inrange(bits // shift): tmp = res ^ tmp >> shift return tmp
# right shift with mask inverse definverse_right_mask(res, shift, mask, bits=32): tmp = res for i inrange(bits // shift): tmp = res ^ tmp >> shift & mask return tmp
# left shift inverse definverse_left(res, shift, bits=32): tmp = res for i inrange(bits // shift): tmp = res ^ tmp << shift return tmp
# left shift with mask inverse definverse_left_mask(res, shift, mask, bits=32): tmp = res for i inrange(bits // shift): tmp = res ^ tmp << shift & mask return tmp
defrecover(y): y = inverse_right(y,18) y = inverse_left_mask(y,15,4022730752) y = inverse_left_mask(y,7,2636928640) y = inverse_right(y,11) return y&0xffffffff
random_number = [] state = [recover(i) for i in random_number]
definvert_right(m,l,val=''): length = 32 mx = 0xffffffff if val == '': val = mx i,res = 0,0 while i*l<length: mask = (mx<<(length-l)&mx)>>i*l tmp = m & mask m = m^tmp>>l&val res += tmp i += 1 return res
definvert_left(m,l,val): length = 32 mx = 0xffffffff i,res = 0,0 while i*l < length: mask = (mx>>(length-l)&mx)<<i*l tmp = m & mask m ^= tmp<<l&val res |= tmp i += 1 return res
definvert_temper(m): m = invert_right(m,18) m = invert_left(m,15,4022730752) m = invert_left(m,7,2636928640) m = invert_right(m,11) return m
defclone_mt(record): state = [invert_temper(i) for i in record] gen = Random() gen.setstate((3,tuple(state+[0]),None)) return gen
prng = []
g = clone_mt(prng[:624]) for i inrange(700): g.getrandbits(32)
defbacktrace(cur): high = 0x80000000 low = 0x7fffffff mask = 0x9908b0df state = cur for i inrange(623,-1,-1): tmp = state[i]^state[(i+397)%624] # recover Y,tmp = Y if tmp & high == high: tmp ^= mask tmp <<= 1 tmp |= 1 else: tmp <<=1 # recover highest bit res = tmp&high # recover other 31 bits,when i =0,it just use the method again it so beautiful!!!! tmp = state[i-1]^state[(i+396)%624] # recover Y,tmp = Y if tmp & high == high: tmp ^= mask tmp <<= 1 tmp |= 1 else: tmp <<=1 res |= (tmp)&low state[i] = res return state
# right shift inverse definverse_right(res,shift,bits=32): tmp = res for i inrange(bits//shift): tmp = res ^ tmp >> shift return tmp
# right shift with mask inverse definverse_right_values(res,shift,mask,bits=32): tmp = res for i inrange(bits//shift): tmp = res ^ tmp>>shift & mask return tmp
# left shift inverse definverse_left(res,shift,bits=32): tmp = res for i inrange(bits//shift): tmp = res ^ tmp << shift return tmp
# left shift with mask inverse definverse_left_values(res,shift,mask,bits=32): tmp = res for i inrange(bits//shift): tmp = res ^ tmp << shift & mask return tmp
defbacktrace(cur): high = 0x80000000 low = 0x7fffffff mask = 0x9908b0df state = cur for i inrange(5,-1,-1): tmp = state[i+624]^state[i+397] # recover Y,tmp = Y if tmp & high == high: tmp ^= mask tmp <<= 1 tmp |= 1 else: tmp <<=1 # recover highest bit res = tmp&high # recover other 31 bits,when i =0,it just use the method again it so beautiful!!!! tmp = state[i-1+624]^state[i+396] # recover Y,tmp = Y if tmp & high == high: tmp ^= mask tmp <<= 1 tmp |= 1 else: tmp <<=1 res |= (tmp)&low state[i] = res return state
defrecover_state(out): state = [] for i in out: i = inverse_right(i,18) i = inverse_left_values(i,15,0xefc60000) i = inverse_left_values(i,7,0x9d2c5680) i = inverse_right(i,11) state.append(i) return state