欧几里得算法(辗转相除法)
在数学中,辗转相除法,又称欧几里得算法(英语:Euclidean algorithm),是求最大公约数的算法。
两个整数的最大公约数是能够同时整除它们的最大的正整数。辗转相除法基于如下原理:两个整数的最大公约数等于其中较小的数和两数相除余数的最大公约数。在这个过程中,较大的数缩小了,所以继续进行同样的计算可以不断缩小这两个数直至其中一个变成零。这时,所剩下的还没有变成零的数就是两数的最大公约数。由辗转相除法也可以推出,两数的最大公约数可以用两数的整数倍相加来表示,如 $21 = 5 × 105 + (−2) × 252$。这个重要的结论叫做裴蜀定理。
在现代密码学方面,它是RSA算法的重要部分。它还被用来解丢番图方程,比如寻找满足中国剩余定理的数,或者求有限域中元素的逆。辗转相除法还可以用来构造连分数,在施图姆定理和一些整数分解算法中也有应用。辗转相除法是现代数论中的基本工具。
1 | def gcd(a, b): |
扩展欧几里得算法
扩展欧几里得算法(英语:Extended Euclidean algorithm)是欧几里得算法(又叫辗转相除法)的扩展。已知整数 $a,b$,扩展欧几里得算法可以在求得$a,b$的最大公约数的同时,能找到整数 $x,y$(其中一个很可能是负数),使它们满足裴蜀定理
$ax + by = \gcd(a, b)$
如果 $a$ 是负数,可以把问题转化成
$|a|(-x)+by=\gcd(|a|,b))$($|a|$ 为 $a$ 的绝对值),然后令 $x’=(-x)$。
通常谈到最大公约数时,我们都会提到一个非常基本的事实(由裴蜀定理给出):给定二个整数 $a,b$,必存在整数 $x,y$ 使得 $ax + by = \gcd(a, b)$。
众所周知,已知两个数 $a$ 和 $b$,对它们进行辗转相除(欧几里得算法),可得它们的最大公约数。不过,在欧几里得算法中,我们仅仅利用了每步带余除法所得的余数。扩展欧几里得算法还利用了带余除法所得的商,在辗转相除的同时也能得到裴蜀等式中的 $x,y$ 两个系数。以扩展欧几里得算法求得的系数是满足裴蜀等式的最简系数。
另外,扩展欧几里得算法是一种自验证算法,最后一步得到的 $s_{i+1}$ 和 $t_{i+1}$ 乘以 $\gcd(a,b)$ 后恰为 $a$ 和 $b$,可以用来验证计算结果是否正确。
扩展欧几里得算法可以用来计算模反元素(也叫模逆元),求出模反元素是RSA加密算法中获得所需公钥、私钥的必要步骤。
1 | def ext_euclid(a, b): |
大步小步算法(BSGS算法)
在群论中,大步小步算法(英语:baby-step giant-step)是丹尼尔·尚克斯发明的一种中途相遇算法,用于计算离散对数或者有限阿贝尔群的阶。其中离散对数问题在公钥加密领域有着非常重要的地位。
许多常用的加密系统都基于离散对数极难计算这一假设——计算越困难,这些系统提供的数据传输就越安全。增加离散对数计算难度的一种方法,是把密码系统建立在更大的群上。
这是一种空间换时间的算法,实质上是求解离散对数的朴素算法(枚举并试乘)的一个相当简单的改进。
大步小步算法常用于求解用于解决解高次同余方程的问题,问题形式如:有同余方程 $a^x \equiv b \pmod p$,$p$ 为质数,求最小非负整数解 $x$ 使得原方程成立。这类问题也称为离散对数问题。该算法的复杂度可以达到 $O(\sqrt{p}\log{n})$ 甚至更低。
原理
根据欧拉定理,我们知道模的剩余类有产生循环的情况,即 $a^0, a^1, \ldots, a^{n-1}$ 模 $n$(质数)意义下的剩余类与 $a^n, a^{n+1}, \ldots, a^{2n-1}$ 的剩余类相同,因此我们要的答案一定在 $[0, n-1]$ 内。
我们考虑先求出一部分 $a$ 的幂次模 $p$ 意义下的值,将它们存起来,然后使得剩下没有求值的部分能够想个办法利用已求值直接查出来。我们想起了根号,不如直接令求值的长度为 $m=\lceil \sqrt{p} \rceil$。
下面要考虑的是没有求值部分怎么来求,比如 $a^m, \ldots, a^{2m-1}$ 这一段,如果有解,一定是 $a^i \cdot a^m \equiv b \pmod{p}$ 的情况,我们把那个 $a^m$ 移到右边来,就变成了 $a^i \equiv b’ \pmod{p}$ 且 $b’ = ba^{-m}$。既然这样,我们为什么不考虑直接查这个 $b’$ 有没有对应的i的答案。这样,没有求值的部分的每一段就可以只进行一次查询来判断该段内是否有解。
这个保存,我们可以用一个map<int,int>来存,$x[i]$ 为余数为 $i$ 的 $a^x$ 中最小的 $x$ 值,则插入查询都为 $O(\log n)$,总复杂度达到 $O(\sqrt{n} \log n)$。当然还可以用HashMap存,复杂度会更优一些。
1 | //C++ |
1 | #python |
扩展大步小步算法(扩展BSGS算法)
原理
$p$ 非质数怎么办呢?并不是说 $p-1$ 以内没有答案,而是 $p$ 可能会很大。想个办法来缩小 $p$ 的范围。
我们想起了一些同余性质,比如
$a \equiv b \pmod{m} \Leftrightarrow \frac{a}{d} \equiv \frac{b}{d} \pmod{\frac{m}{d}}$,其中 $d$ 为 $a,b,m$ 的正公因数。我们想办法如此提公因数。
从方程左边拆一个 $a$ 出来,提公因数,提完就变成这样一个式子
$a^{x-1} \cdot \frac{a}{d} \equiv \frac{b}{d} \pmod{\frac{p}{d}}$。直到某个时候 $\mathrm{gcd}(a, \frac{p}{\prod_i d_i}) = 1$。
如果在提公因数的过程中,遇到 $\mathrm{gcd}(a, \frac{p}{\prod_i d_i}) \neq 1$ 且 $d$ 不能整除 $b$ 的情况,说明式子无解。
因为 $a^x, p$ 中的一个共同的因数$b$中没有,显然不存在这样的 $b$。
结束以后,我们得到的会是一个这样的式子
$a^{x-k} \cdot \frac{a^k}{\prod_i d_i} \equiv \frac{b}{\prod_i d_i} \pmod{\frac{p}{\prod_i d_i}}$
把分母搞掉
$a^x \equiv b \pmod{\frac{p}{\prod_i d_i}}$
这个直接扔给普通BSGS做就好了。
1 |
|
威尔逊定理
在初等数论中,威尔逊定理给出了判定一个自然数是否为质数的充分必要条件。即:当且仅当p为质数时:
$ (p-1)! \equiv -1 \pmod p$
但是由于阶乘是呈爆炸增长的,其结论对于实际操作意义不大。
推论
$ (p-2)! \equiv 1\pmod p$
欧拉定理
在数论中,欧拉定理(也称费马-欧拉定理或欧拉$\varphi$函数定理)是一个关于同余的性质。欧拉定理表明,若 $n,a$ 为正整数,且 $n,a$ 互素(即 $\gcd(a,n)=1$),则
$a^{\varphi (n)}\equiv 1{\pmod n}$
即 $a^{\varphi (n)}$ 与 $1$ 在模 $n$ 下同余;$\varphi (n)$ 为欧拉函数。欧拉定理得名于瑞士数学家莱昂哈德·欧拉。
欧拉定理实际上是费马小定理的推广。
费马小定理
费马小定理是数论中的一个定理。
假如 $a$ 是一个整数,$p$ 是一个质数,那么 $a^p-a$ 是 $p$ 的倍数,可以表示为:
$a^p \equiv a \pmod p$
如果 $a$ 不是 $p$ 的倍数,这个定理也可以写成:
$a^{p-1} \equiv 1 \pmod p$
这个书写方式更加常用。
费马商
在费马小定理中,$\frac{a^{p-1}-1}{p}$ 显然是一个整数。 这个整数被称作 $p$ 的以 $a$ 为基的费马商(Fermat Quotient),记作 $q_p(a)$。
性质
(其中 $a,b$ 和 $p$ 互素)
$q_p(ab) \equiv q_p(a)+q_p(b) \pmod p$
$q_p(a^r) \equiv rq_p(a) \pmod p$
$q_p(p \mp 1) \equiv \pm 1 \pmod p$
$q_p(p \mp a) \equiv q_p(a) \pm \frac{1}{a} \pmod p$
$-2q_p(2) \equiv -\sum\limits_{k = 1}^{p-1} \frac{(-1)^{k-1}}{k} \pmod p = 1+\frac{1}{2}+\cdots+\frac{1}{\frac{p-1}{2}} \pmod p = \sum\limits_{k = 1}^{\frac{p-1}{2}} \frac{1}{k} \pmod p$
二次剩余
二次剩余(Quadratic Residue)常被称为模意义开根,是求满足 $x^2 \equiv a \pmod p$ 的值。
并不是对每个 $a$ 而言上面的方程都有解。如果上面的方程有非零解,我们称 $a$ 是模 $p$ 的二次剩余。如果方程无解,则称 $a$ 是模 $p$ 的二次非剩余。
欧拉准则
$\left(\cfrac ap\right) \equiv a^{\frac {p-1}2} \pmod p$
勒让德符号 (Legendre Symbol)
$L(a,p)=\left(\frac ap\right)=\left\{\begin{array}{cl}1,&\mbox{若 }
a\mbox{ 是 } p \mbox{ 的二次剩余}\newline 0,
&\mbox{若 }a \bmod p = 0\newline -1,&\mbox{若 }
a\mbox{ 是 } p \mbox{ 的二次非剩余}\end{array}\right.$
性质
$\left(\cfrac ap\right) = \left(\cfrac {a \pm p}p\right) = \left(\cfrac {a \bmod p}p\right)$
$\left(\cfrac {ab}p\right) = \left(\cfrac ap\right)\left(\cfrac bp\right)$
$\left(\frac {-1}p\right)=\left\{\begin{array}{cl}1,& p \equiv 1 \pmod 4 \newline -1,
& p \equiv 3 \pmod 4 \end{array}\right.$
$\left(\frac 2p\right)=\left\{\begin{array}{cl}1,& p \equiv \pm 1 \pmod 8 \newline -1,& p \equiv \pm 3 \pmod 8 \end{array}\right.$
$\left(\cfrac pq\right)\left(\cfrac qp\right) = (-1)^{\frac{p-1}2{\frac{q-1}2}}$
$\sum\limits_{x=0}^{p-1}\left(\cfrac{ax+b}p\right)=0,p\nmid a$
$\sum\limits_{x=0}^{p-1}\left(\cfrac{ax^2+bx+c}p\right) = \left\{\begin{array}{cl}-\left(\cfrac ap\right),& p \nmid b^2-4ac \newline (p-1)\left(\cfrac ap\right),
& p \mid b^2-4ac \end{array}\right.$
参考:Some sums of Legendre’s symbols
雅可比符号 (Jacobi Symbol)
$J(a,p) = \left(\cfrac an\right)= \prod\limits_{i=1}^{m} \left(\cfrac a{p_i}\right)^{t_i},n = \prod\limits_{i=1}^{m} p_i^{t_i}$
性质
$\left(\cfrac an\right) = \left(\cfrac {a \pm n}n\right) = \left(\cfrac {a \bmod n}n\right)$
$\left(\cfrac {ab}n\right) = \left(\cfrac an\right)\left(\cfrac bn\right)$
$\left(\cfrac {-1}n\right)= (-1)^{\frac{n-1}2}$
$\left(\cfrac 2n\right)= (-1)^{\frac{n^2-1}8}$
中国剩余定理(孙子定理 / CRT)
定义
用现代数学的语言来说明的话,中国剩余定理给出了以下的一元线性同余方程组:
$(S):\left\{\begin{array} {c} x \equiv a_1 \pmod {m_1} \\ x \equiv a_2 \pmod {m_2} \\ \vdots \\ x \equiv a_n \pmod {m_n} \end{array} \right.$
有解的判定条件,并用构造法给出了在有解情况下解的具体形式。
说明
假设整数 $m_1,m_2,…,m_n$ 其中任两数互质,则对任意的整数:$a_1,a_2,…,a_n$,方程组 $(S)$ 有解,并且通解可以用如下方式构造得到:
设 $M=m_1×m_2×\dots×m_n=\prod\limits_{i=1}^{n} m_i$ 是整数 $m_1,m_2,…,m_n$ 的乘积,并设 $M_i=\cfrac{M}{m_i},\forall i \in \{1,2,…,n\}$,即 $M_i$ 是除了 $m_i$ 以为的 $n-1$ 个整数的乘积。
设 $t_i=M_i^{-1}$ 为 $M_i$ 模 $m_i$ 的数论倒数:$t_iM_i \equiv 1 \pmod {m_i},\forall i \in \{1,2,…,n\}$。
方程组 $(S)$ 的通解形式为:
$x=a_1t_1M_1+a_2t_2M_2+\dots+a_nt_nM_n+kM=kM+\sum\limits_{i=1}^{n}a_it_iM_i,\quad k\in \mathbb{Z}$
在模 $M$ 的意义下,方程组 $(S)$ 只有一个解:$x=\sum\limits_{i=1}^{n}a_it_iM_i$。
模不两两互质的同余式组可化为模两两互质的同余式组,再用孙子定理直接求解。
1 | #sage |
扩展中国剩余定理(扩展CRT / ExCRT)
中国剩余定理是用来解同余方程组的,它要求 $m_1,m_2,…,m_n$其中两两互质。
模不两两互质的同余式组可化为模两两互质的同余式组,再用中国剩余定理直接求解。
形式
给定 $n$ 组非负整数 $m_i, a_i$ ,求解关于 $x$ 的方程组的最小非负整数解。
$\left\{\begin{array} {c} x \equiv a_1 \pmod {m_1} \\ x \equiv a_2 \pmod {m_2} \\ \vdots \\ x \equiv a_n \pmod {m_n} \end{array} \right.$
解法
扩展中国剩余定理的方法和中国剩余定理关系不大,我们贪心处理前 $i-1$ 项,然后合并当前方程。
将每个方程拆成若干个方程 $x=a_i \pmod {p_{i,j}^{k_{i,j}}}$,其中 $m_i=\prod p_{i,j}^{k_{i,j}}$ 为$m_i$ 的分解式。
对每个质数 $p$,合并对应的所有方程,从而转化为模数两两互质的情形。若合并过程中出现矛盾,则原方程组无解。
1 | #互质与不互质两种情况下都能工作良好的中国剩余定理(解同余方程组) |
变种1:Noisy CRT
$L_i=\frac{\prod p_i}{p_i} \cdot \Big((\frac{\prod p_i}{p_i})^{-1} \bmod p_i \Big)$
$N \equiv \sum\limits_{i=1}^{n}\sum\limits_{j=1}^{m} \delta_{i,j}r_{i,j}L_i \pmod {\prod p_i}, \delta = \{0,1\}$
构造格:
$M =
\begin{bmatrix}
P & 0 & \cdots & \cdots & 0 & \newline
r_{1,1}L_1 & B & 0 & \cdots & 0 & \newline
r_{1,2}L_1 & 0 & B & \ddots & \vdots & \newline
\vdots & \vdots & \ddots & \ddots & 0 & \newline
r_{n,m}L_n & 0 & \cdots & 0 & B & \newline
\end{bmatrix}$
$B$ 主要是为了优化格,只需随意选取和 $N$ 的bit相同的数 $2^k$ 即可,目标向量为 $(N,\delta_{1,1}B,\delta_{1,2}B,\cdots,\delta_{n,m}B)$。
参考:
Noisy Polynomial Interpolation and Noisy Chinese Remaindering
DeadSec CTF 2023 - Loud系列
费马因式分解
引理:如果 $n$ 是一个正奇数,那么 $n$ 分解为两个正整数的积和表示成两个平方数是一一对应的。
即:$n=ab=x^2-y^2=(x+y)(x-y)=\left(\cfrac{a+b}{2}\right)^2-\left(\cfrac{a-b}{2}\right)^2$。
因为 $n$ 为奇数,$a,b$ 必也为奇数,所以 $(a+b)$ 和 $(a-b)$ 必为偶数,故能被 $2$ 整除。
算法
从 $x=\lceil\sqrt{n}\rceil+k,k \in \mathbb{Z}$ 开始,当 $(x^2-n)$ 可被完全开方,即 $x^2-n=y^2$ 时,即求出 $(x,y)$。
1 | import gmpy2 |
1 | from gmpy2 import * |
高斯整数
高斯整数 $\mathbb{Z}[i]=\{a+bi \mid a,b \in \mathbb{Z}\}$。
对于 $z=x^2+y^2=(x+yi)(x-yi)=(y+xi)(y-xi)$,且满足 $z=(a_1+b_1i)^t(a_1-b_1i)^t \cdots (a_k+b_ki)^t(a_k-b_ki)^t$,可用于分解 $z$ 求得 $x,y$。
1 | z = |
1 | N = |
CopperSmith攻击
算法描述:
假设 $N$ 是一个未知因子组成的数,且存在一个因子 $b \ge N^{\beta},(0 \lt \beta \le 1)$,$f(x)$ 是一个一元一次 $d$ 阶的多项式,且 $c \ge 1$,那么可以在 $\text{O}(cd^5\log^9(N))$ 的复杂度内求解所有的 $x_0$。
$f(x_0) \equiv 0 \pmod b, x_0 \le cN^{\frac{\beta^2}{d}}$
Coppersmith攻击与Don Coppersmith紧密相关,他提出了一种针对于模多项式(单变量,二元变量,甚至多元变量)找所有小整数根的多项式时间的方法。我们的目标是找到在模 $N$ 意义下多项式所有的根,这一问题被认为是复杂的,即满足下式的根:
$F(x)=x^n+a_{n-1} x^{n-1}+ ···+ a_1 x+a_0 \equiv 0 \pmod N$
Coppersmith method 主要是通过 Lenstra–Lenstra–Lovász lattice basis reduction algorithm(LLL)方法。
Coppersmith攻击可解根上界:$N^{\frac{\beta^2}{d}-\epsilon}$。
$d$ 为待求解多项式的阶,$\beta$ 为有限域 $\mathbb{Z}(p)$ 上多项式中 $p$ 满足 $p>N^{\beta}$,$\epsilon$ 是调节参数。
参数的选取问题:
- $p\geq N^{\beta}$,因为$p\cdot q = N,p\neq q$,$\beta$的取值可以略小于$\frac{1}{2}$,例如$0.49$。
- 小根$x_0$的上界$X$,选取$X=2^{K}$,$K$ 为未知位数。
- $\varepsilon$的取值,可以选取$\epsilon=\frac{\beta^2}{\delta}-\log_{N}(2\cdot X)$。实际上,可以略微将$\epsilon$的值提升一点,可以有效降低时间开销。
1 | #Sage |
Gröbner基
空间和域
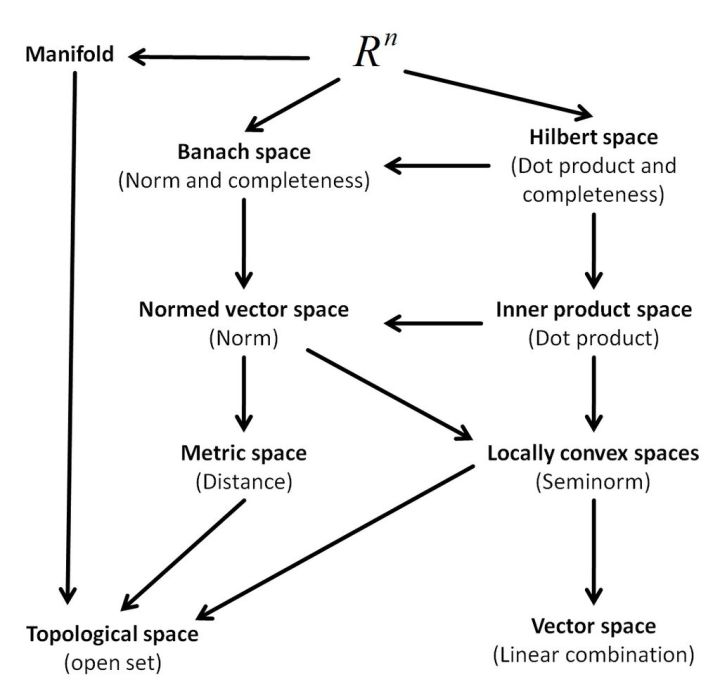
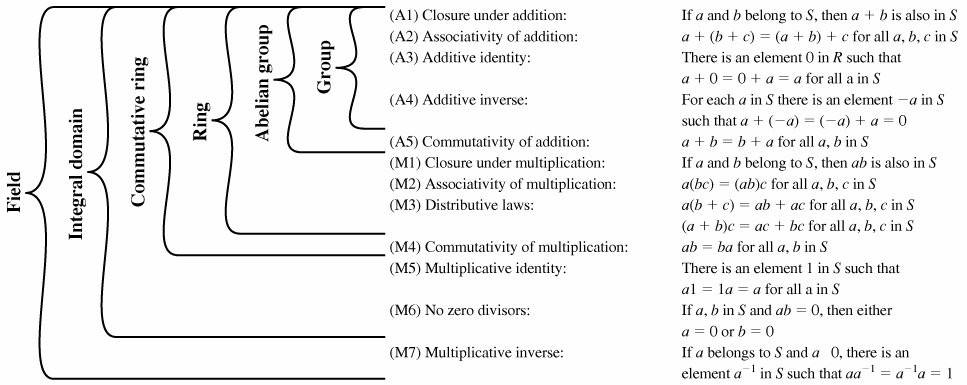
理想
$F=\{f_1,\cdots,f_k\}$ 是一个多项式集合,其生成的理想为集合元素的线性组合,组合系数也是多项式
$\langle f_1,\cdots,f_k \rangle=\biggl\{ \sum\limits_{i=1}^k g_if_i \vert g_1,\cdots,g_k \in K[x_1,\cdots,x_n] \biggr\}$,
其中 $R=K[x_1,\cdots,x_n]$ 是在域 $K$ 上的多项式环。
环 $R$ 的一个非空子集 $I$ ,如果对于 $R$ 的两个代数运算,满足条件:对任意 $a,b \in I,r \in R$,有 $a-b \in I,ra \in I$,则称 $I$ 是环 $R$ 的一个左理想。
环 $R$ 的一个非空子集 $I$ ,如果对于 $R$ 的两个代数运算,满足条件:对任意 $a,b \in I,r \in R$,有 $a-b \in I,ar \in I$,则称 $I$ 是环 $R$ 的一个右理想。
环 $R$ 的一个非空子集 $I$ ,如果既是左理想又是右理想,称 $I$ 为 $R$ 的双边理想,通常简称 $I$ 为 $R$ 的理想。
根据以下定理,每个理想都有一个生成集:
Hilbert 基定理:
每个多项式理想 $I \subseteq K[x_1,\cdots,x_n]$ 都有一个有限生成集,即存在 $g_1,\cdots,g_t \in I$,使得 $I=\langle g_1,\cdots,g_t \rangle$。
Gröbner基定义
对于单项式序下的多项式环 $K[x_1,\cdots,x_n]$,理想 $I \subseteq K[x_1,\cdots,x_n]$ 的非 $\{0\}$ 且满足 $\langle \mathrm{LT}(g_1),\cdots,\mathrm{LT}(g_t) \rangle=\langle \mathrm{LT}(I) \rangle$ 的有限生成集 $G=\{g_1,\cdots,g_t\}$,称为Gröbner基。定义 $\{0\}$ 的Gröbner基为空集 $\varnothing$。
Gröbner基的两个应用,判断一个多项式是否属于当前的Gröbner基生成的理想 (即Ideal Membership problem),另一个应用就是解方程组。
1 | #Sage |
Diffie-Hellman密钥交换(DH密钥交换 / DHKE)
Diffie-Hellman密钥交换(DHKE)是由Whitfield Diffie和Martin Hellman在1976年提出的。密钥交换方案提供了实际中密钥分配问题的解决方案,即允许双方通过不安全的信道进行交流获得一个共同密钥。许多公开和商业密码协议中都实现了这种基本的密钥协议技术。
基于乘法群:
- A和B协商一个有限循环群 $G$ 和它的一个生成元 $g$,一个大素数 $p$;
- A生成一个随机数 $a$,计算 $A=g^a \pmod p$,将 $A$ 发送给B;
- B生成一个随机数 $b$,计算 $B=g^b \pmod p$,将 $B$ 发送给A;
- A计算 $K=B^a \pmod p=(g^b)^a \pmod p$,得到共享密钥 $K$;
- B计算 $K=A^b \pmod p=(g^a)^b \pmod p$,得到共享密钥 $K$。
基于加法群:
- A和B协商一个有限循环群 $G$ 和它的一个生成元 $g$,一个大素数 $p$;
- A生成一个随机数 $a$,计算 $A=ag \pmod p$,将 $A$ 发送给B;
- B生成一个随机数 $b$,计算 $B=bg \pmod p$,将 $B$ 发送给A;
- A计算 $K=aB \pmod p=a(bg) \pmod p$,得到共享密钥 $K$;
B计算 $K=bA \pmod p=b(ag) \pmod p$,得到共享密钥 $K$。
矩阵快速幂
根据斐波那契的递推公式:
$\left\{\begin{array}{cl} f(n)&=&f(n-1)+f(n-2) \\ f(n-1)&=&f(n-1) \end{array}\right. \Rightarrow \begin{bmatrix} f(n) \\ f(n-1) \end{bmatrix}=\begin{bmatrix} 1 & 1 \\ 1 & 0 \end{bmatrix}\begin{bmatrix} f(n-1) \\ f(n-2) \end{bmatrix}$
设 $\begin{bmatrix} f(n) \\ f(n-1) \end{bmatrix}=F(n)$,则 $F(n)=\begin{bmatrix} 1 & 1 \\ 1 & 0 \end{bmatrix} \cdot F(n-1)$
把矩阵当成一个常数来看,即类似等比数列递推公式,即:
$\begin{bmatrix} f(n) \\ f(n-1) \end{bmatrix}=\begin{bmatrix} 1 & 1 \\ 1 & 0 \end{bmatrix}^{n-1}\begin{bmatrix} f(1) \\ f(0) \end{bmatrix}$
所以最终转换成一个求解矩阵幂运算的通项公式。
普通快速幂算法:
1 | int qpow(int x, int n, int m) { |
根据矩阵乘法运算改写为矩阵快速幂:
1 |
|
其他递推关系
$f(n)=af(n-1)+bf(n-2)\Longrightarrow \begin{bmatrix} f(n) \\ f(n-1) \end{bmatrix}=\begin{bmatrix} a & b \\ 1 & 0 \end{bmatrix}\begin{bmatrix} f(n-1) \\ f(n-2) \end{bmatrix}$
$f(n)=af(n-1)+bf(n-2)+c \Longrightarrow \begin{bmatrix} f(n) \\ f(n-1) \\ c \end{bmatrix}=\begin{bmatrix} a & b & 1 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{bmatrix}\begin{bmatrix} f(n-1) \\ f(n-2) \\ c\end{bmatrix}$
$f(n)=ac^n+bf(n-1)+d \Longrightarrow \begin{bmatrix} f(n) \\ c^n \\ d \end{bmatrix}=\begin{bmatrix} b & ac & 1 \\ 0 & c & 0 \\ 0 & 0 & 1 \end{bmatrix}\begin{bmatrix} f(n-1) \\ c^{n-1} \\ d\end{bmatrix}$
$S(n)=A \cdot S(n-1)+A\Longrightarrow \begin{bmatrix} S(n) \\ A \end{bmatrix}=\begin{bmatrix} A & E \\ 0 & E \end{bmatrix}\begin{bmatrix} S(n-1) \\ A \end{bmatrix}$
1 | #以2x2矩阵相乘为例 |
佩尔方程 / Pell方程
若一个不定方程具有形式:
$x^2-ny^2=1$
则称此二元二次不定方程为佩尔方程。
若 $n$ 是完全平方数,则这个方程式只有平凡解。对于其余情况,拉格朗日证明了佩尔方程总有非平凡解。而这些解可由 $\sqrt{n}$ 的连分数求出。
设 $\frac{p}{q}$ 是 $\sqrt{n}$ 的连分数表示:$[a_0;a_1,a_2,a_3,\cdots]$ 的渐进分数列,由连分数理论知存在 $i$ 使得 $(p_i,q_i)$ 为佩尔方程的解。取其中最小的 $i$,将对应的 $(p_i,q_i)$ 称为佩尔方程的基本解(最小解),记作 $(x_1,y_1)$,则所有的解 $(x_i,y_i)$ 可表示成如下形式:
$x_i+y_i\sqrt{n}=(x_1+y_1\sqrt{n})^i$
或者由以下的递推式得到:
$x_{i+1} = x_1x_i+ny_1y_i$
$y_{i+1} = x_1y_i+y_1x_i$
1 | def solve_pell(N, numTry = 100): |

